 In my recent articles on how outcomes are assessed in clinical studies I have covered the minimal clinically important difference (MCID), a measure of how large a change in the patient’s condition needs to be to justify using an intervention, assuming a good benefit to harm balance and cost-effectiveness; the minimal important difference (MID), a similar measure, omission of the word “clinically” being intended to focus attention on the patient rather than the clinician; the size of the difference, which should be, but is not always, important to the patient, and may be important to others, such as family or carers, or even the clinician; and the patient acceptable symptom state (PASS), a rarely used term, intended to focus on “the highest level of symptom beyond which patients consider themselves well”.
In my recent articles on how outcomes are assessed in clinical studies I have covered the minimal clinically important difference (MCID), a measure of how large a change in the patient’s condition needs to be to justify using an intervention, assuming a good benefit to harm balance and cost-effectiveness; the minimal important difference (MID), a similar measure, omission of the word “clinically” being intended to focus attention on the patient rather than the clinician; the size of the difference, which should be, but is not always, important to the patient, and may be important to others, such as family or carers, or even the clinician; and the patient acceptable symptom state (PASS), a rarely used term, intended to focus on “the highest level of symptom beyond which patients consider themselves well”.
I concluded that it would be helpful to introduce two new concepts to clarify the ideas that the various terms imply: minimum desirable benefits and maximum acceptable harms. These terms imply that what is acceptable to the patient (or family or carers) in terms of beneficial outcomes may not be what the patient actually wants, and that whatever the patient wants in the way of benefit must be tempered by the realization that harms can occur and that what matters is not either the desire to achieve benefit nor the hope of avoiding harms, but a combination of the two, commonly expressed as the benefit to harm balance.
Having then considered reported outcomes I thought it worth going on to consider primary and secondary outcomes or endpoints. And here a cautionary tale is relevant. Having completed ISIS-2, a randomized trial of intravenous streptokinase, oral aspirin, both, or neither in 17 187 patients with suspected acute myocardial infarction, Richard Peto and his colleagues submitted the manuscript to the Lancet. It was accepted, but on condition that subgroup analyses be included. Peto demurred, but the journal insisted, so he agreed, but slipped in an analysis of subgroups according to their astrological birth sign. Peto later published the complete data in the British Journal of Cancer (Figure 1).

Figure 1. A subgroup analysis of the results of ISIS-2 by astrological birth sign (from Peto, 2011); the authors of the ISIS-2 study had described these results in their paper as follows: “for patients born under Gemini or Libra there was a slightly adverse effect of aspirin on mortality while for patients born under all other astrological signs there was a strikingly beneficial effect”.
The Lancet’s insistence in this case was surprising, The dangers of subgroup analyses and ways of dealing with them were already well known. For example, John Tukey published his range test for multiple comparisons in analysis of variance in 1949 and Olive Jean Dunn published what became known as the Bonferroni correction technique in 1961.
One consequence of this understanding was that it became de rigueur to identify in advance the outcomes in clinical trials, details of which were to be collected and analysed, as described in the first CONSORT statement in 1996. In a parallel development, the division of outcomes into primary and secondary, to be prespecified and analysed and interpreted separately, was introduced into clinical trials by at least the 1980s (Figure 2). The earliest example I have found dates from 1985, although it was already a concept in management. Furthermore, primary and secondary outcomes were undoubtedly specified before then in trials that were published only later. For example, the prospective study known as the UKPDS, which reported primary and secondary outcomes starting in the 1990s, randomized its first patients in the late 1970s.
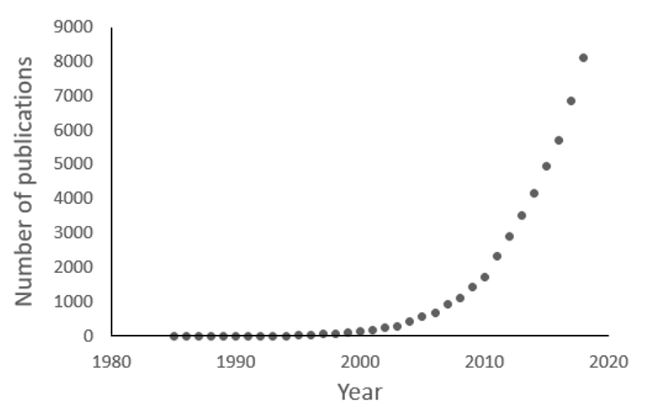
Figure 2. Numbers of publications since 1985 containing the terms “primary outcomes/endpoints” and “secondary outcomes/endpoints” (source textwords in PubMed)
The primary outcome is the one that the trialists decide is a priority. The sample size is then calculated assuming a predicted desirable, or simply attainable, effect size and the sizes of the type 1 and type 2 errors. If the trial is large enough, it may be possible to make judgements about the secondary endpoints, if positive effects occur. Even if the results are negative, some conclusions may be possible, depending on the confidence intervals. An arbitrarily large study would be likely to be sufficiently powered to allow conclusions about at least some of the secondary outcomes, although it might be impossible to make accurate calculations in advance, if the anticipated effect sizes are not known or if some endpoints are rare (e.g. adverse effects or adverse reactions).
One way of approaching this problem would be to choose a core set of outcomes for specific problems, which could be duplicated across all relevant studies and about which enough is known to allow calculations to be made in advance. This and other aspects of outcomes, such as composite outcomes, biomarkers, and inappropriate or misleading reporting of outcomes, require separate consideration.
Acknowledgements: Thanks for helpful comments from my colleagues in the Centre for Evidence Based Medicine in Oxford, Kamal Mahtani, Annette Plüddemann, and Richard Stevens.
Jeffrey Aronson is a clinical pharmacologist, working in the Centre for Evidence Based Medicine in Oxford’s Nuffield Department of Primary Care Health Sciences. He is also president emeritus of the British Pharmacological Society.
Competing interests: None declared.