 Somehow science managed to struggle through several thousand years, having considerable impact as it went (think electricity, atomic power, penicillin), without either defining or measuring impact, but now measuring the impact of research is becoming de rigueur.
Somehow science managed to struggle through several thousand years, having considerable impact as it went (think electricity, atomic power, penicillin), without either defining or measuring impact, but now measuring the impact of research is becoming de rigueur.
The Research Excellence Framework (“The REF,” as everybody calls it) measures the research performance of British universities and awards 25% of its score (and subsequent funding) based on a measure of impact. icddr,b [formerly the International Centre for Diarrhoeal Disease Research, Bangladesh], where I’m the chair of the board, is trying to measure it, and so I was keen to attend a meeting in Oxford on research impact. As I travelled back on the train I met a charming woman who told me that she was a medical astrologer and was attending a conference of the British Astrological Society. I couldn’t stop myself wondering if our two meetings might be more similar than dissimilar.
What is research impact?
I define research impact as “real change in the real world.” In terms of health it means fewer deaths; better quality of life; more effective treatments; reduced costs; or improvements in surrogate or process outcomes, like more people being treated for hypertension or quicker access to general practitioners. Importantly, as well the impact is beyond the research process. A large clinical trial may have considerable impact on those included in the trial, but impact is what happens beyond the trial.
The REF has to measure impact across the full academic range, meaning in opera and dance as well as in cardiology or mechanical engineering. It defines impact thus: “an effect on, change or benefit to the economy, society, culture, public policy or services, health, the environment or quality of life, beyond academia.”
The Oxford meeting stayed away from defining research impact. People preferred impacts to impact. Rather than impacts being thought of as “positive, big, and muscular,” they would be better thought of as “incremental, pluralistic, and contested.” Simple definitions “drive a lot of bollocks,” feared one researcher.
Some preferred “value” to “impact”: value depends on perspective, which was thought fine. But impact too depends on perspective: the National Institute for Health Research is primarily interested in impact with the NHS (this was yet another meeting where healthcare was seen as the same thing as health); the Wellcome Trust might want high quality and transformative research; the Treasury economic return; and patients improvement in their conditions.
I was left thinking that we at iccdr,b may have been too concrete in defining research impact. Indeed, I ought to confess that measuring research impact at icddr,b is seen as my pet project and may well disappear after I leave the board at the end of the year.
Why measure research impact?
Why should we try to measure the impact of research? I think that for icddr,b it’s easy to answer. We do research to improve the health of the Bangladeshi people and people in other low and income countries. Many of our funders are funding development. They want improvements beyond the research. Increasingly, that’s true as well of research funders: they are about change, not just papers in journals—the main traditional way of measuring research performance.
I say to our researchers that a paper in Nature and the world is just the same as failure, whereas real improvement in the health of Bangladeshis and a publication in a local journal or no publication at all is success. I overstate my case for researchers, who dream of a paper in Nature.
Mark Taylor, head of impact at the National Institute for Health Research, said that there are four broad reasons for measuring impact: advocacy, accountability, analysis, and allocation. The results might be used to advocate with funders, government, the public, or others. Measuring impact is a form of accountability, showing that something is being achieved. Or the results can be used for analysing which forms of research are producing most impact and perhaps for allocating resources, possibly allocating more to those who have more impact. All of these reasons apply at icddr,b. The long term aim is to increase the impact of our research.
Taylor talked as well about being clear about who impact was being measured for and sees three broad categories: macro, meso, and micro. Macro means government—government departments or the equivalent. Examples of meso organisations are the National Institute for Health and Care Excellence (NICE) or clinical commissioning groups, while micro covers patients, clinicians, or other researchers.
How can research impact be measured?
But how can research impact be measured? In contrast to measuring numbers of publications and citations, which is easy and can be automated, measuring impact (whatever it might be) is hard. Trish Greenhalgh, professor of primary care in Oxford, has identified 21 different methods but said that they boiled down into three broad categories; economic, methods used by social scientists, and methods used by business schools.
All the methods have to consider how science works and impact happens; some assume a linear model, while everybody recognises that linear development, from idea through research to impact, is a simplification of a much more complex process—“science meanders,” said Greenhalgh. Nevertheless, she said, everybody tends to fall back on the linear model; more complex models, including those developed by social scientists, may reflect more accurately how science and impact happens but are harder to use.
Then there is the question of whether to use metrics or narrative. If a simple, number based system of measuring impact could be developed it would probably assume as much importance as the measurement of publications and citations—but nobody has developed such a system; and it’s almost certainly impossible to do so. Thus a near consensus has been reached that “narratives with numbers” is the best method.
But there’s also consensus that researchers find it hard to write compelling accounts of impact. The REF defines a specific way in which the report must be presented with a word length of less than 1000 words; plus it must be written in a way that anybody could read.
Academics used to writing in the “decorated municipal gothic” of academic English find it difficult to write in plain English. Then a good story grabs and convinces you, whereas traditional science papers are deliberately constructed not to overdo the significance of the findings and are full of caveats. Retaining the caveats but telling a compelling story is not easy. Finding the numbers to include in the story can be difficult, and attribution is also difficult—most changes result not from single studies or even collections of studies from one institution but from multiple factors, many of them not research studies at all.
Researchers at icddr,b, writing impact case reports for the first time, found it difficult, and one group that had had major impact on reducing deaths across several countries failed to describe the impact in their report.
Because of the difficulties of writing the reports and the great importance of the reports, universities try to find people with the necessary skills. It may well be that a market develops in writing or at least editing the reports.
Another tension in measuring impact is between outcomes and processes. Ideally when measuring the impact of health research we would measure reduced deaths and suffering and improved quality of life. But such outcomes may not result for decades, while processes—like inclusion of research findings in guidelines or policies—may happen quickly.
Greenhalgh presented the results of her analysis of the impacts described in 162 case studies submitted from community based health sciences as part of the 2014 Research Excellence Framework. The majority described changes in processes rather than outcomes (see figure).
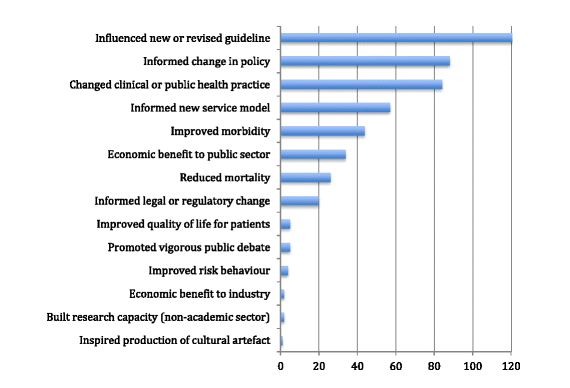
Timing is another problem in measuring research impact. Impact often takes years, so what should be the time limits for a measurement exercise? We struggled with this at icddr,b and didn’t get it right. The REF asks for impact in the past seven years of research conducted in the past 20 years. We should perhaps follow that. There was also confusion over whether to start with the research or the impact, but we eventually decided to start with impact.
How we measured impact at icddr,b?
At icddr,b we decided not to reinvent the wheel but to use the system developed by the REF with some adaptations. We made presentations to researchers on what we meant by impact, why it mattered, and how we were going to measure it. We emphasised all the way along that the exercise was a “work in progress,” but many researchers were sceptical.
Nevertheless, researchers did produce reports, and a committee of a government representative, a funder, the head of a major NGO in Bangladesh, a member of the centre’s Scientific Advisory Group, the executive director of icddr,b, and two board members, one of whom was me, scored the reports.
I devised a scoring system, which is below.
Scoring impact of icddr,b research
Level five—highest impact
- Objective evidence of health improvements in outputs like reduced deaths, improved quality of life, reduced hospital admissions, or reduced attendances at health clinics
or
- Objective evidence of reduced costs with health outputs improved or the same
or
- Income to icddr,b or government of Bangladesh with health outputs improved or the same
- Many people have benefited
- Benefit in more than five countries
Level four
- As above only benefit in only one country or one part of a country (but beyond are studied in the original research)
Level three
- Objective evidence of health improvements in surrogate endpoints like blood pressure, vaccination rates, smoking rates, access to clean water, number of toilets, Caesarean section rates etc
or
- Objective evidence of reduced costs with surrogate endpoints improved or the same
or
- Income to icddr,b or government of Bangladesh with surrogate endpoints improved or the same
- Many people have benefited
- Benefit in more than five countries
Level two
- As above only happening in only one country or one part of a country
Level one—lowest impact
- No evidence yet of benefit to health but, for example, research is included in guidelines or has led to a change in government policy that has yet to be shown to have an impact on health
- No effect in reducing costs
- No income to icddr,b
- Happening in only one country (presumably Bangladesh) or one part of a country
Each member of the committee scored the reports individually before the meeting, and there was high agreement on the scores. We found results similar to those Greenhalgh found—many examples of changes in guidelines and policies but few examples of where lives had been saved, although there were some.
We decided after the first round that we will increase the scale from five points to seven—with three rather than one level at the bottom. Level one would be discussion of results in something like government or WHO; level two would be something like incorporation into guidelines or policies; and level three would be a more concrete improvement in the health system like a new way of gathering and using data. We will probably also reduce the requirement for “benefit in five countries” to “three countries.”
Messages from the meeting
Discussion at the Oxford meeting ranged widely, and I left the meeting more confused than when I arrived. That, however, is probably no bad thing. I used to regularly end talks with the observation of Jack Welch, once chief executive of General Electric, that “If you are not confused you don’t know what is going on.” (Think Brexit.)
One take-home message was around gaming. Whatever system you devise for measuring performance those being measured will game the system—and those who are best at gaming may not be the best performers. Indeed, people may put more energy into gaming than performing well. This is one of the ways that that a system might achieve the opposite of what it is intended to achieve. The system of measuring academics has led to salami publishing of poor quality studies, frank misconduct, and the propping up of an outdated way of publishing science.
But gaming also relates to a second take-home message: the importance of training researchers, particularly young researchers, in having impact, influencing decision makers, and writing strong impact case reports. Although some might concentrate on gaming the system, more might put emphasis on increasing the impact of research—exactly the outcome intended.
Another important message was about involving patients in measuring impact—and, indeed, in designing and evaluating research. We haven’t done this at icddr,b, and I can’t think of any group in low and middle income countries where this is happening. I’d like to see it happen at icddr,b.
My ultimate take-home message was that when trying to measure and increase the impact of research (or when doing most things) “the process of engaging people is more important than the product.” I fear that I might have been too heavy handed and dictatorial at icddr,b and that as a result the attempt to measure research impact may be shelved when I step down as chair at the end of the year.
Richard Smith was the editor of The BMJ until 2004.
Competing interest: RS paid his own expenses to attend the Oxford meeting, but did get a free lunch from Jesus College. He is not paid as the chair of icddr,b, although his expenses to attend meetings, including a business class return to Dhaka, are paid. He will leave the board at the end of the year.