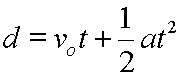 No, not -1, the self-multiplication of that fancy imaginary number that helps aircraft designers make wings work properly, but a (semi) quantitative assessment of how much heterogeneity there is in a meta-analysis: I²
No, not -1, the self-multiplication of that fancy imaginary number that helps aircraft designers make wings work properly, but a (semi) quantitative assessment of how much heterogeneity there is in a meta-analysis: I²
You’ll recall that the idea of heterogeneity (mixed-up-ness) comes in both statistical and clinical flavours. This measure – I² – assesses the statistical aspect. It’s often to be found at the bottom of a forest plot, near some other numbers (Tau² and Chi²).
The principle of I² is straightforward – it gives you an idea of the ‘percentage of variation which is beyond that you’d expect by chance alone’. It can be interpreted, approximately*, like this:
0-25% – just chance, really
25-50% – bit more than just chance, but unless clinically odd, probably OKish. With a grain of salt.
51%+ – Woah! Really quite different. Should you be doing a summary estimate here at all?
(Flashback again – the underlying assumption of fixed effect meta-analysis is that the only variation between the studies is chance. Random effects gives you an average effect over an average population in an average trial .. etc etc ..)
There are problems with I²; if there are very few studies (<5) it probably underestimates heterogeneity, and if there are lots of studies (>40 or so) then it certainly overestimates it. And it’s actually a point estimate in itself (and should be given with its own confidence interval … but that’s just too complicated to try ..). And it’s not really giving you a value you can assess the absolute amount of ‘extra’ to try to assess how clinically meaningful that ‘beyond chance’ness would be. But frankly, if those sorts of things really bother you, then you’ll probably be able to interpret Tau² directly and calculate your own prediction intervals.
– Archi
* There are other versions. For example