In the second of two blogs, Jeff Aronson considers how the word “data” is used in bioscience publications and discusses who owns data and collections of data.
Usage
 Whether we can use etymology or grammar to settle the question of the singularity or plurality of “data” (it appears to be both), we can determine how people use the word. To do this, I have searched PubMed for instances of “data are” compared with “data is” and for instances of “these data” compared with “this data”. The results are shown, year by year since 1960, in Figure 1. The plural forms are overwhelmingly used in the bioscience literature indexed in PubMed, and although there has been a drift towards the use of the singular forms, the plural is still overwhelmingly used in preference.
Whether we can use etymology or grammar to settle the question of the singularity or plurality of “data” (it appears to be both), we can determine how people use the word. To do this, I have searched PubMed for instances of “data are” compared with “data is” and for instances of “these data” compared with “this data”. The results are shown, year by year since 1960, in Figure 1. The plural forms are overwhelmingly used in the bioscience literature indexed in PubMed, and although there has been a drift towards the use of the singular forms, the plural is still overwhelmingly used in preference.
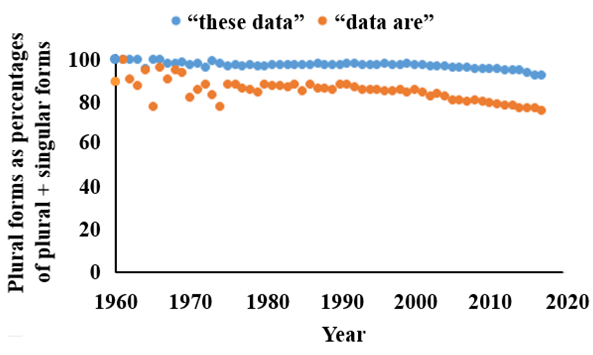
Figure 1. The frequencies of the plural terms “these data” and “data are”, compared with the singular terms “this data” and “data is”, expressed as the percentages of all plural plus singular instances 1960–2017 (source PubMed)
However, what your discipline is, determines your usage, as Table 1 shows. I used truncated address terms to distinguish different disciplines (for example, “Comput*” for Departments of Computing or Computational Science etc). Those in the statistical/ mathematical/ computing fields are much more likely to use singular “data” than preclinical scientists, clinicians, and epidemiologists. When each address term was used to the exclusion of all the others (i.e. eliminating papers in which combinations of disciplines were represented), the percentage results were exactly the same. When any of the statistical/ mathematical/ computing definers was combined with any of the others, plural usages were reduced to 79% (3506 versus 847 hits), suggesting a modifying influence of the former group on the latter.
There was a small variation across different language groups (Table 1), but the data are hard to interpret because of problems with translation.
Table 1. Preferences for plural or singular usages of “data” according to specialty and language group, defined by address terms in PubMed
| Group (truncated address terms) | Plural usage | Singular usage | Plural hits as a percent of total number of hits |
| All data | 542 504 | 47 171 | 92% |
| Specialties | |||
| Pharmac* | 29 735 | 1294 | 96% |
| Pathol* | 18 575 | 1014 | 95% |
| Biochem* | 18 540 | 1100 | 94% |
| Clinic* OR Medic* | 204 448 | 13 271 | 94%† |
| Veterinar* | 8098 | 555 | 94% |
| Epidemiol* | 8476 | 1096 | 89% |
| Statist* | 3205 | 919 | 78% |
| Math* | 2218 | 889 | 71% |
| Comput* | 4968 | 2408 | 67% |
| Language groups | |||
| Latin | 54 335 | 4113 | 93% |
| English | 225 128 | 19 485 | 92% |
| Greek | 1849 | 216 | 90% |
| Germanic | 50 545 | 6048 | 89% |
| Slavic | 7241 | 1026 | 88% |
| Finno-Ugric | 4044 | 536 | 88% |
† In the clinical/medical grouping, the data were stable across all subspecialties (91–96%).
Nowadays everybody is talking about “big data”, referring to enormous collections of individual pieces of data, more of an idea than a specific thing as such. Some, therefore, find it natural to refer to “big data” as a singular object, as here: “Today big data has an important place in healthcare, including in pharmacovigilance”. If this usage continues it will tend to strengthen the use of “data” itself as a singular noun. However, the term is still being used as a plural in bioscience publications. When I looked for “big data” as a phrase in the titles of papers indexed in PubMed, I found over 1700 examples; five used “is” (for example, “Big Data is changing the battle against infectious diseases”) and two used “are” (for example, “Big data are coming to psychiatry: a general introduction”). This is too small a sample for a clear conclusion, but, given the huge preference for “are” with “data” on its own, it suggests that people tend to regard “big data” as a single entity, like “database” or “databank”.
So is “data” singular or plural? Etymology, grammar, and usage all say plural, although there may be some instances when the singular form can be used. My own preference is to regard “data” as a plural and to use singular words such as “database” to describe a collection of plural data.
Who owns the data?
The answer to the apparently minor question of whether “data” is singular or plural actually informs the answer to a much more important and difficult question: who owns the data (the individual items) or the database (the collection)?
Consider individual sets of data collected during a clinical trial or the data in patients’ medical records. Those, I suggest, belong to the patient and no-one else. That is why anonymization of individual sets of data within collections of data is important. No individual owns anybody else’s set of data, only their own. However, it is implicit in the collection of such data that the collector also has some interest in the collection. For example, it is proper that a GP or a clinician under whose care the patient came under while in hospital should be asked for permission for the patient’s records to be released to the patient, since those records will contain material, other than information about the patient, relevant to the clinician; however, it would generally be expected that such permission would readily be given, unless there were very good reasons otherwise. The same might be true when being asked to release the records to others; in that case, the permission of both the patient and the clinician would be required. Patients who bring law-suits must expect that their data will be made available to the opposition under common legal practice.
But who owns the anonymized collection of all data? Those who appear to have a claim to ownership include those who have collected them (GPs or hospital doctors, the trialists in a clinical trial, or those who are recipients of individual case reports, for example, regulatory agencies collecting reports of suspected adverse reactions) and those who have funded studies. The former might include principal investigators, co-investigators, the members of independent data monitoring committees, and other researchers. The latter might be, for example, a drug company, a philanthropic institution, or a governmental or charitable grant-giving organization. Of course, the right that such organizations have is balanced by the reciprocal duty of taking proper care of the data, not, for example, revealing them to others without the permission of the individual owner and without taking care to protect anonymity.
The question of who profits is intimately connected to this question. It might be argued that the individuals whose data or resources are being used for profit have some right to that use. This was argued in the case of the group of anticancer medicines called taxanes after they had been discovered in the bark of the Pacific yew tree. That particular Gordian knot was irreversibly cut when derivatives were synthesized, removing the need to harvest the trees.
The linguistic analysis above suggests that data should be regarded as the individual bits of information relevant to distinct individuals, but that a collection of such data can be regarded as a single object. So, in summary, my answer to the question of who owns data is that each individual owns his or her own. My answer to the question of who owns an anonymized collection of data is that no one individual or institution does, although those who collected the data or paid to have them collected may have a legitimate claim. However, in these days of transparency, it would be equally justifiable to take the view that collections of data should be shared and that communally everybody owns them. Having collected the data I have a social obligation to make them generally available. I respect patients’ autonomy by ensuring that the data are anonymized.
Jeffrey Aronson is Associate Editor BMJ EBM, consultant physician and clinical pharmacologist, and Fellow of CEBM
Conflict of Interest: none declared
Previous in the series: A Word About Evidence: 7. Data—etymology and grammar
Read more in the Word about evidence series